
teaching is only demonstrating that it is possible. learning is making it possible for yourself -Paulo Coelho-
Kadang kala kita abai akan pentingnya proses 'belajar', yang kita harapkan hanya kesuksesan tanpa harus bersusah payah mewujudkan nya. bahkan di cerita dongeng sekalipun, happy ending tidak hadir begitu saja, selalu ada kisah pilu yang mengantarkan kita pada cerita indah di akhir. *ini lagi ngebahas apaan yak -_-
by the way, ini adalah kesempatan yang jarang saya dapatkan, di mana saya bisa tergerak kembali untuk menambah khazanah postingan di blog tercinta. pada postingan kali ini, saya akan fokus untuk membahas konsep 'Data Mining', spesifiknya yang saya akan coba share adalah penerapan algortima Apriori dalam lingkup aturan asosiasi (Association Rule Learning).
Association Rule Learning
Bicara soal Association Rule ( Aturan Asosiasi), tidak lepas dari analisis asosiasi dimana konsep sebab-akibat (antecedant-consequent) menjadi poin penting dalam menghasilkan aturan-aturan asosiasi. Association Rule merupakan pendekatan eksplorasi data yang sering digunakan atau diterapkan pada kumpulan data yang sangat besar. Aturan asosiasi tersebut setidaknya menyediakan informasi berharga dalam menilai korelasi antar data secara signifikan.
Untuk memudahkan pemahaman, saya ambil contoh data keranjang belanja pembeli di sebuah grosir. Pada setiap transaksi pembelian yang dilakukan oleh konsumen akan tercatat ID transaksi dan pada setiap transaksi memungkinkan ada satu atau lebih barang ( item) yang dibeli. Dapat dibayangkan jika setiap hari terdapat 100 transaksi, maka dalam sebulan setidaknya ada 3000 transaksi yang tercatat dan tersimpan di dalam database. Nah, disinilah peran Association Rule diterapkan untuk membaca pola atau kecendrungan pembelian konsumen. Misalnya, dari 100 transaksi, ada sekitar 50 transaksi yang dilakukan konsumen dengan pola yang sama, yaitu konsumen akan membeli minyak jika telur juga dibeli. Hal ini tentunya Sejalan dengan tujuan aturan asosiasi, yang memungkinkan kita untuk memperoleh informasi mengenai item/barang apa saja yang konsumen sering beli bersamaan. Di mana informasi tersebut akan digunakan oleh pihak manajemen grosir untuk membuat kebijakan seperti : pertama, pihak manajemen dapat melakukan replace pada barang/item yang sering dibeli bersamaan, agar mudah dilihat dan diakses oleh konsumen. Misalnya, telur dan minyak sering dibeli bersamaan, maka pihak manajemen dapat mengatur tempat peletakan telur dan minyak berdekatan agar memudahkan konsumen dalam membeli keduanya. Kedua, pihak manajemen dapat melakukan promosi terhadap produk yang jarang dibeli untuk mengurangi stok yang menumpuk di gudang. ketiga, hal ini tentu berhubungan dengan manajemen stok, dimana pihak manajemen dapat membuat keputusan untuk memperbanyak stok barang/item yang sering dibeli agar tidak terjadi penumpukan.
So, inti dari aturan asosiasi ini adalah terbentuknya aturan sebab-akibat yang dapat diterapkan dalam menarik informasi yang memiliki korelasi signifikan. Dalam aturan asosiasi, ada 2 poin penting yang harus dijabarkan untuk menghasilkan aturan yang tepat.
Nilai Support
Nilai Support (s) merupakan persentase jumlah kasus untuk kombinasi item tertentu.

Dimana X∪Y merupakan jumlah transaksi yang berisi X dan Y, sementara N merupakan total jumlah seluruh transaksi. Nilai support menjadi ukuran yang sangat penting dalam aturan asosiasi karena aturan yang sangat lemah nilai support-nya berarti asosiasi tersebut sangat jarang terjadi dalam dataset (seluruh data transaksi).
Nilai Confident
Nilai Confident (c) merupakan persentase keakurasian dari aturan asosiasi yang dihasilkan.

Dimana X∪Y merupakan jumlah transaksi yang berisikan X dan Y, sementara X merupakan jumlah transaksi yang berisikan X. Nilai confident yang tinggi menggambarkan banyaknya Y yang muncul dalam transaksi yang berisi X.
Gimana ? sudah mulai pusing ? rileks dulu bro n sis *saya tarik nafas dulu yak.
Agar tidak tambah pusing saya akan langsung mencontohkan ke contoh kasus sederhana.
Berikut ada 8 data transaksi keranjang belanja dari sebuah grosir seperti pada tabel berikut.

Untuk menghasilkan aturan asosiasi setidaknya ada 2 fase yang harus dilakukan terkait penggunaan nilai support dan confident di atas :
Frequent itemset
Fase pertama, adalah menentukan itemset yang frequent, frequent disini maksudnya adalah kombinasi itemset yang sering muncul dalam dataset (data transaksi). sehingga aturan yang dibuat nantinya mampu menghasilkan nilai confident yang tinggi.
Kembali ke contoh kasus tersebut, kita akan mulai mencari itemset yang frequent. Dengan melakukan kombinasi itemset yang mungkin berdasarkan k-itemset ( pembangkitan itemset frequent), k disini mengacu pada jumlah item yang akan dikombinasikan.
k-itemset ( k=1)
kita mulai dari pembangkitan itemset k=1, maka itemset yang dapat dibentuk beserta dengan jumlah kemunculan nya dalam seluruh transaksi sebagai berikut :
Jelas bahwa dari 8 transaksi pembelian dicontoh, ada 6 transaksi yang membeli item beras, 4 transaksi membeli item buku, 6 transaksi membeli item minyak, 6 transaksi membeli item telur dan 3 transaksi membeli item topi.Beras = 6Buku=4Minyak=6Telur=6Topi=3
k-itemset (k=2)
lanjut pada tahap iterasi kedua dengan nilai k=2, berarti kita akan membentuk kombinasi dari 2 buah itemset sebagai berikut :
Dari 8 transaksi pembelian pada contoh, setidaknya ada 2 dari 8 transaksi yang membeli item Beras dan Buku bersamaan, 4 transaksi membeli item Beras dan Minyak, 5 Transaksi membeli item Beras dan Telur, dan begitu selanjutnya.{Beras,Buku} = 2{Beras,Minyak}=4{Beras,Telur}=5{Beras,Topi}=2{Buku,Minyak}=3{Buku,Telur}=2{Buku,Topi}=1{ Telur,Minyak}=5{Minyak,Topi}=2{Telur,Topi}=2Dan seterusnya……
k-itemset (k=3)
kemudian pada iterasi ketiga dengan nilai k=3, akan dibentuk kombinasi dari 3 buah itemset sebagai berikut :
Dari 8 transaksi pada contoh, terdapat 4 transaksi yang membeli item {telur,minyak dan beras} bersamaan, 2 transaksi yang membeli item {telur,minyak dan buku},2 transaksi yang membeli item {telur,minyak dan topi} dan selanjutnya.{Telur,Minyak,Beras}=4{Telur,Minyak,Buku}=2{Telur,Minyak,Topi}=2{Telur,Beras,Buku}=1{Telur,Beras,Topi}=2{Beras,Buku,Topi}=0{Beras,Topi,Minyak}=2{Beras,Buku,Minyak,}=1{Buku,Minyak,Topi}=1Dan seterusnya…….
k-itemset (k=4)
terakhir pada iterasi keempat dengan nilai k=4, akan dibentuk kombinasi dari 4 buah itemset sebagai berikut :
Dari 8 transaksi pada contoh, terdapat 1 transaksi yang membeli item {telur,minyak,beras dan buku} bersamaan, 1 transaksi yang membeli item {telur,minyak,beras dan topi} bersamaan dan selanjutnya.{Telur,Minyak,Beras,Buku}=1{Telur,Minyak,Beras,Topi}=2{Telur,Minyak,Buku,Topi}=0Dan seterusnya…..
Bisa dibayangkan hanya untuk 8 transaksi dengan maksimal item yang dibeli setiap transaksi adalah 4 item saja bisa menghasilkan 31 kombinasi asosiasi. Gimana jika tidak menggunakan konsep asosiasi? Mungkin bisa sampai (8x4x31) =992 peluang, gimana jika ada ribuan transaksi ? *makin puyeng euyy.
Well, pada tahap itemset frequent kita sudah menghasilkan setidaknya 31 kombinasi itemset yang menjadi kandidat. Selanjutnya kita bisa menghitung nilai confident untuk setiap kandidat itemset frequent yang akan dijadikan sebagai aturan-aturan asosiasi jika nilai confident-nya tinggi.
Ekstraksi Aturan Asosiasi
Setelah didapatkan kombinasi itemset yang frequent, maka fase selanjutnya adalah mengekstrasi aturan asosiasi dari kombinasi itemset yang memiliki nilai confident yang tinggi.
Untuk menghitung nilai confident, setidaknya kita juga mesti menghitung nilai supportnya agar terlihat korelasi antara nilai support dan nilai confident tersebut. Sebagai contoh kita akan menghitung nilai support dan confident dari k-itemset (k=2) berikut :
dapat dilihat dari contoh perhitungan di atas, hal tersebut akan terus kita lakukan untuk menentukan nilai support dan confident untuk ke 31 kandidat itemset frequent yang lain. Akan memakan waktu sekali, namun coba lihat dari contoh perhitungan di atas. Ada korelasi yang bisa kita tarik hipotesa nya untuk memudahkan kita dalam menentukan aturan asosiasi yang tepat sesuai dengan konsep algoritma Apriori.{Beras,Buku} = 2s(Beras->Buku) = 2/8 = 0.25 = 25%c(Beras->Buku)=2/6 = 0.33 = 33%{Beras,Telur}=5s(Beras->Telur) = 5/8 = 0.625= 62.5%c(Beras->Telur)=5/6 = 0.83 = 83%
Algoritma Apriori
Algoritma Apriori adalah algoritma yang cukup efisien dalam menentukan jumlah itemset frequent, prinsip dasar dari algoritma ini adalah jika sebuah itemset itu merupakan itemset frequent, maka semua subset (bagian) dari itemset tersebut juga frequent dan juga sebaliknya. Contohnya, jika itemset A tidak frequent (tidak sering muncul dalam transaksi), maka item apapun yang dikombinasikan ke itemset A tidak akan membuat itemset A menjadi frequent (sering muncul dalam transaksi). Nah, hal inilah yang dimanfaatkan oleh algoritma Apriori untuk mengurangi/mempersempit ruang pencarian kandidat itemset frequent. Hal ini tentu ditandai dengan pembatasan pada nilai ambang batas untuk nilai support (minSupport). Seperti pada contoh perhitungan sebelumnya, dapat ditarik kesimpulan bahwa, nilai support yang rendah akan mempengaruhi nilai confident. Contoh : nilai support untuk itemset ( Beras->Buku) adalah 25%, minim nya nilai support tersebut ternyata berpengaruh pada nilai confident nya yang hanya 33%. Tentu untuk itemset tersebut tidak layak dijadikan sebagai salah satu aturan asosiasi dikarenakan nilai akurasi nya hanya 33%. Tentu saja, aturan-aturan yang minim nilai confident ini yang akan dipangkas oleh algoritma Apriori sehingga nantinya yang dihasilkan adalah aturan-aturan asosiasi yang memiliki nilai confident yang sesuai.
Agar tidak bosan membaca penjelasan saya, mari kita eksekusi contoh transasksi sebelumnya.
Pada Algortima Apriori, langkah pertama yang harus dilakukan adalah :
Menentukan nilai minimum Support
Misalkan nilai minimum support yang akan kita terapkan adalah minSupport=4 ( setara dengan 4/8 = 0.5 atau 50% )
Maka pada iterasi pertama k-itemset (k=1) akan terbentuk aturan sebagai berikut :
Beras = 6Buku=4Minyak=6Telur=6Topi=3
Dari kelima itemset tersebut, item topi ( 3/8 = 0.375 atau 37.5%) tidak memenuhi nilai minimum support=50 %. Sehingga pada iterasi kedua k-itemset (k=2). Semua itemset yang mengandung topi juga akan dieliminasi sesuai dengan prinsip algoritma apriori.
Pada k-itemset (k=2) di atas, itemset {Beras,Buku} ( 2/8=0.25 atau 25%), {Buku,Minyak} ( 3/8=0.375 atau 37.5%) dan {Buku,Telur} ( 2/8=25%) tidak memenuhi nilai minimum support, sehingga itemset tersebut juga dieliminasi. Pada iterasi ketiga k-itemset (k=3) hanya tersisa 1 itemset yang memenuhi minimum nilai support yaitu itemset {Telur,Minyak,Beras} ( 4/8 =0.5 atau 50%){Beras,Buku} = 2{Beras,Minyak}=4{Beras,Telur}=5{Beras,Topi}=2{Buku,Minyak}=3{Buku,Telur}=2{Buku,Topi}=1{ Telur,Minyak}=5{Minyak,Topi}=3Dan seterusnya……{Telur,Topi}=3
Berdasarkan algoritma Apriori, maka aturan asosiasi yang berhasil didapatkan adalah sebagai berikut :{Telur,Minyak,Beras}=4{Telur,Minyak,Buku}=2{Telur,Minyak,Topi}=2{Telur,Beras,Buku}=1{Telur,Beras,Topi}=2{Beras,Buku,Topi}=0{Beras,Topi,Minyak}=2{Beras,Buku,Minyak,}=1{Buku,Minyak,Topi}=1Dan seterusnya…….
1. {Beras,Minyak}Nilai confident, c(Beras->Minyak) = 4/6 = 0.67 = 67%2. {Beras,Telur}Nilai confident, c(Beras->Telur) = 5/6 = 0.83 = 83%3. {Minyak,Telur}Nilai confident, c(Minyak->Telur) = 5/6 = 0.83 = 83%4. {Telur,Minyak,Beras}Nilai confident, c(Telur,Minyak->Beras) = 4/5 = 0.67 = 80%
Aturan Asosiasi :
1. If Beras, Maka Minyak
2. If Beras, Maka Telur
3. If Minyak, Maka telur
4. If Telur dan Minyak, Maka Beras
Gimana bro n sis ?? ribet yak ? *kepala saya udah mau pecah malah. Over all, inilah contoh sederhana yang bisa saya share seputar penerapan algoritma apriori pada Association Rule, semoga informasi ini bermanfaat untuk temen-teman semua yang sedang mempelajari algoritma ini. Akhir kata saya mohon maaf jika ada kekeliruan atau kesalahan terkait informasi yang saya share di atas, please correct me if I am wrong ya guys.
sumber
Prasetyo, E. (2012). Data Mining konsep dan Aplikasi menggunakan MATLAB. Yogyakarta: Andi.
Larose, D. T. (2015). Data mining and predictive analytics. John Wiley & Sons.
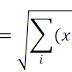

.png)
{kind=link}
5 Comments
jadi kesimpulanya apa bang? mohon dijawab ya untuk membantu tugas saya hehe
ReplyDeletepada saat K-itemset (K=2)nilai {Telur,Topi}=3, seharusnya nilainya {Telur,Topi}=2
ReplyDeletesupport yaitu itemset {Telur,Minyak,Beras} ( 4/8 =0.5 atau 50%)
ReplyDeleteNilai confident, c(Telur,Minyak->Beras) = 4/5 = 0.80 = 80%
kok gak sama ?
Belajar algoritma pemrograman : https://www.samuelpasaribu.com
ReplyDeletecukup mudah dimengerti
ReplyDeleteJangan Lupa Tinggalkan Komentar, Mohon berkomentar yang positif.